Choosing the Right LLM for Each Step in Your Workflow
Using the same model for every step in an AI workflow is the path of least resistance. It is also a significant source of unnecessary cost and latency. A frontier model doing sentiment classification is like using a racing car to get groceries — technically it works, but you are paying for capabilities you are not using.
Production AI systems route tasks to models the way a good engineering team routes work to people: match the complexity of the task to the capability required, not to the most capable option available.
The model tier mental model
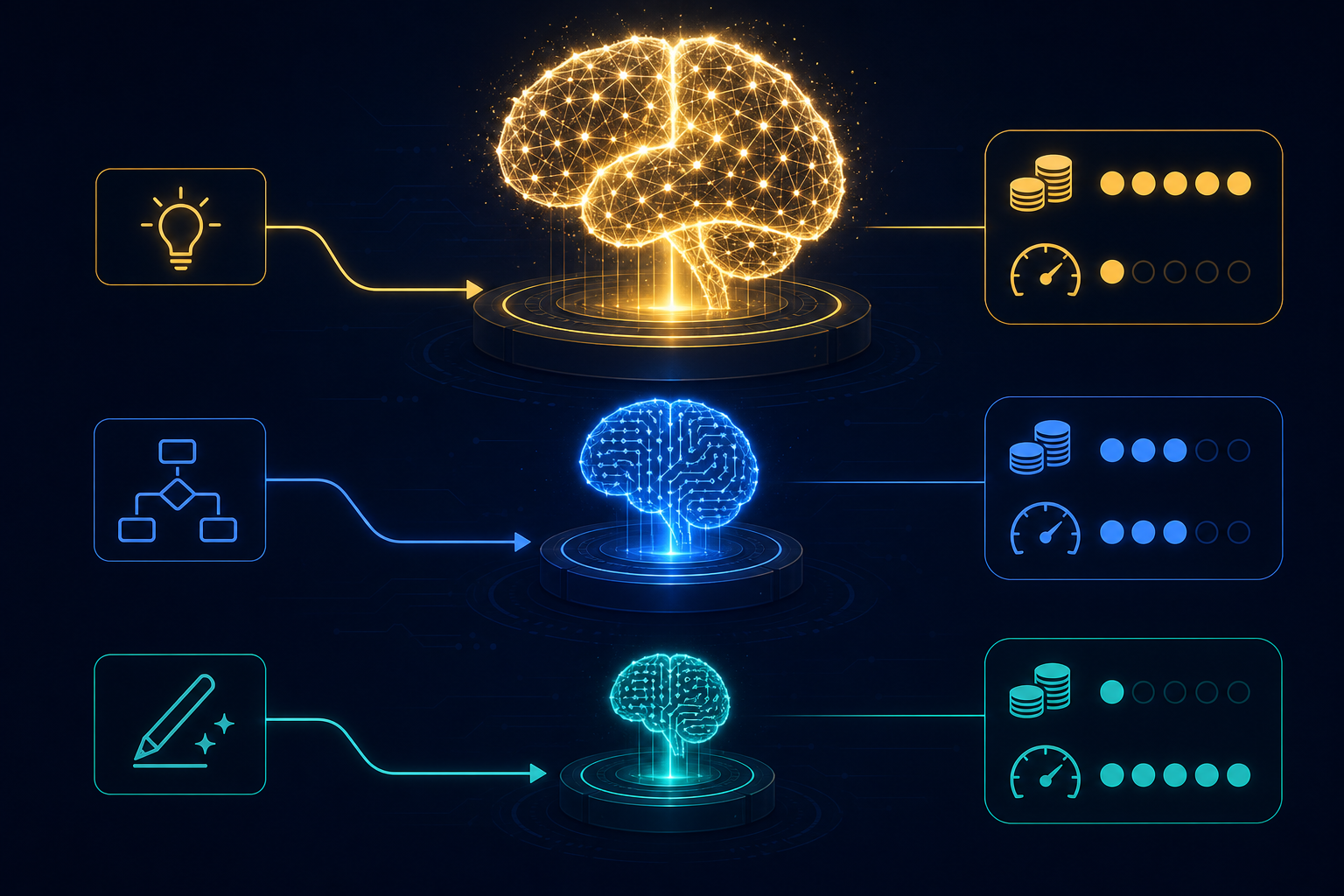
Think of your available models as a hierarchy with three rough tiers:
Tier 1 — Frontier models (GPT-4o, Claude Opus, Gemini Ultra): highest capability, highest cost, highest latency. Use for tasks that require sophisticated reasoning, complex instruction following, nuanced judgment, or where quality directly impacts business outcomes.
Tier 2 — Capable mid-range models (Claude Haiku, GPT-4o mini, Gemini Flash): strong general capability, significantly lower cost and latency. Use for most structured tasks: classification, extraction, summarization, drafting with clear constraints.
Tier 3 — Specialized or fine-tuned models: purpose-built for a narrow task, fastest and cheapest within that task, but fragile outside it. Use when you have a high-volume, well-defined task and the investment in fine-tuning is justified.
The practical question for each step in your workflow: what is the minimum model tier that reliably produces correct output for this task?
Classification and routing are almost always over-modeled
The most common example of model over-use: using a frontier model to classify an inbound support ticket into one of five categories. This task — given a short text, pick the best-matching category from a fixed list — is solved reliably by a mid-range model at a fraction of the cost.
A rule of thumb: if the task can be described as "pick from a fixed list" or "extract these specific fields," start with Tier 2. Escalate to Tier 1 only if the output quality is measurably insufficient.
When frontier models are worth it
Tasks that genuinely require frontier capability:
- Multi-step reasoning — the model needs to reason through several sub-problems, holding intermediate conclusions
- Complex judgment calls — evaluating a contract clause, assessing a security vulnerability, writing nuanced customer-facing content
- Instruction following under ambiguity — the task has edge cases that require interpreting intent, not just following explicit rules
- High-stakes generation — where the quality bar is high and errors are expensive
For these tasks, the cost of using a cheaper model and getting lower-quality output exceeds the cost difference. The calculus reverses.
The latency dimension
Cost and capability are the obvious dimensions. Latency is often overlooked.
A workflow step that calls a frontier model with a large context may take 15–30 seconds. A mid-range model on the same task may take 2–5 seconds. In a workflow with five LLM steps, the difference between all-Tier-1 and mixed tiering can be the difference between a 2-minute run and a 10-minute run.
For user-facing workflows where perceived speed matters, latency is often a stronger driver of model selection than cost.
Model selection as a workflow configuration
Model selection should be explicit in workflow configuration — not hard-coded in application logic. When a model is updated, deprecated, or when a new option becomes available, you want to change the model in one place, not hunt through code.
It should also be monitorable: tracking cost and latency per model per step over time makes model selection decisions data-driven rather than intuition-driven.
AgentRuntime supports per-step LLM configuration — model, provider, temperature, and retry policy — with cost and latency metrics per step surfaced in run traces. Join the waitlist for early access.