Retry Logic for AI Agents: Beyond try/catch
Every developer knows to retry on failure. What most miss is that naive retries are often worse than no retries at all — and in AI workflows, a badly implemented retry can mean a duplicate order, a double payment, or an email sent twice to the same customer.
Getting retries right in AI agents requires thinking about three things most tutorials skip entirely.
The problem with simple retries
A try/catch with a loop handles the happy path: the operation fails transiently, the retry succeeds, the workflow continues. But consider what happens when the operation actually succeeds — the external API call goes through — but the response is lost in transit. Your code sees an exception. It retries. The operation runs again. Now you have submitted the same action twice.
This is not a hypothetical. It is one of the most common causes of production incidents in AI systems that interact with external APIs.
Idempotency keys are the only real fix
An idempotency key is a stable, unique identifier attached to every external call. When the downstream service receives a request with a key it has already processed, it returns the previous result without re-executing the action.
Every external call in a reliable AI workflow should carry an idempotency key derived from the run ID and step name — something like run-{runID}-step-{stepName}. This makes the call replay-safe regardless of what failed and when.
Stripe, Braintree, and most serious payment APIs support this. Many internal APIs do not. When they do not, you need to implement it yourself — which means tracking completion state in a store before the downstream call returns.
Exponential backoff with jitter
When retrying after a failure, a fixed delay causes thundering herd problems under load. All workers fail at the same time, all retry at the same interval, and the pressure wave hits the downstream service in unison.
The standard approach is exponential backoff — each retry waits twice as long as the previous — with added jitter, a small random offset that spreads retries across time.
delay = min(base * 2^attempt + rand(0, 100ms), max_delay)
For LLM API calls specifically, rate-limit responses (HTTP 429) deserve their own retry class: longer initial backoff, respect the Retry-After header when present, and don't burn retry budget on capacity errors that will clear in seconds.
Retry budgets and dead-letter queues
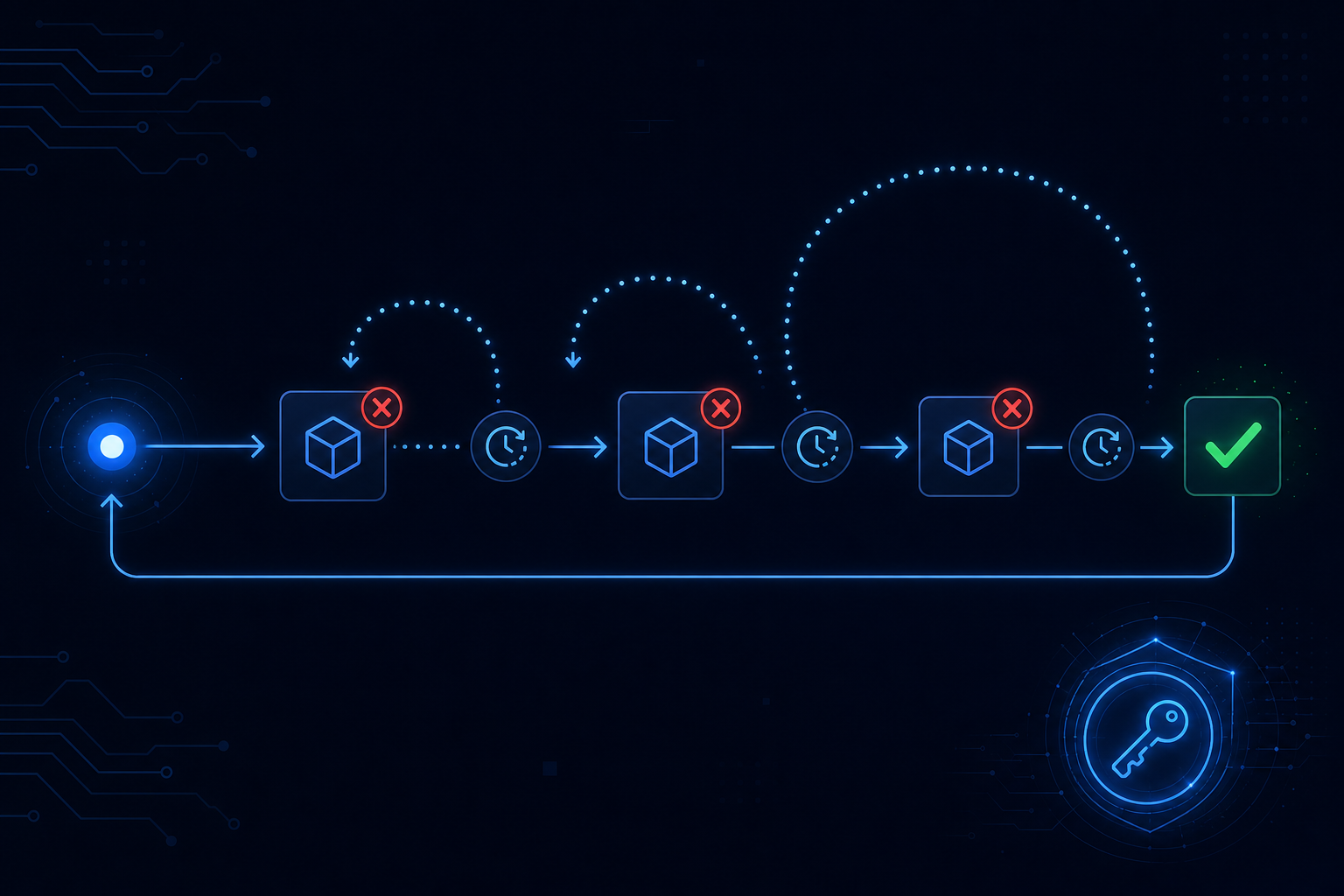
Infinite retries are a system design smell. Every retryable operation should have a maximum attempt count, and failed runs that exceed it should be routed to a dead-letter queue or flagged for human review — not silently dropped.
This matters more for AI workflows than for traditional services because the consequences of silent failure are harder to detect. An agent that quietly stopped halfway through enriching a CRM record may not surface until a sales rep calls the wrong contact three weeks later.
What this looks like in practice
A well-instrumented retry in an AI workflow:
- Assigns a stable idempotency key before the first attempt
- Commits the attempt to a persistent store so a crash mid-retry is recoverable
- Uses exponential backoff with jitter for transient errors
- Separates rate-limit retries from network-error retries
- Routes to dead-letter after N attempts with full context attached
Building this from scratch is non-trivial. The subtle cases — what happens when a step crashes after the external call succeeded but before the result was committed — are where production systems break.
AgentRuntime handles retry semantics at the runtime level: every step carries an idempotency key derived from the workflow run, backoff policies are configurable per step, and failed runs land in an inspectable dead-letter state with full traces. Join the waitlist for early access.