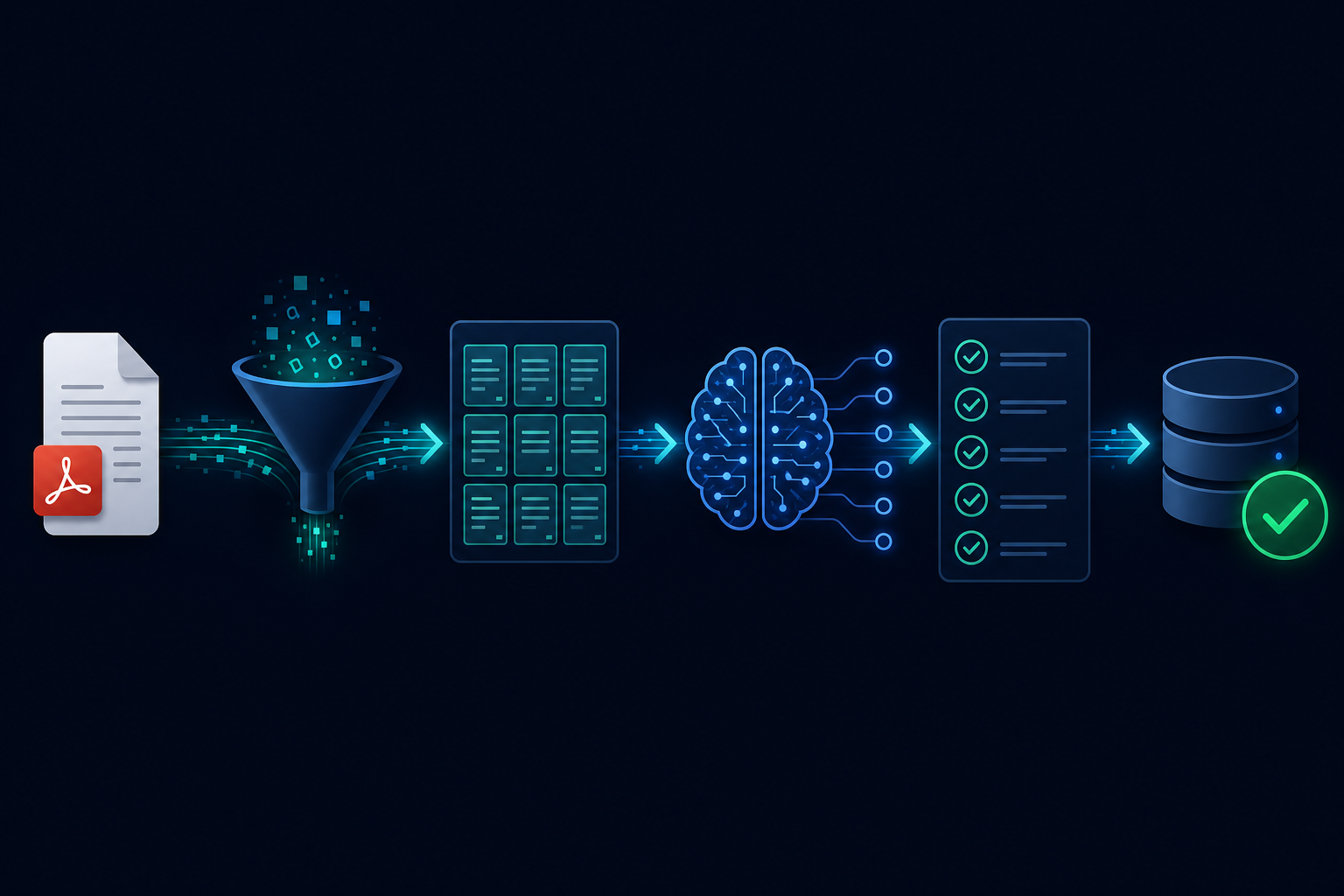
Building a Document Processing Pipeline with AgentRuntime
Document processing is one of the highest-ROI applications of AI in the enterprise. Legal teams reviewing contracts, finance teams extracting data from invoices, HR teams parsing resumes, compliance teams auditing filings — the volume is enormous and the work is repetitive enough that automation is clearly worth it.
But document processing pipelines are harder to build reliably than they look. The documents are heterogeneous, the extraction is imperfect, and the downstream systems that consume the output are unforgiving about data quality.
The pipeline stages
A production document processing workflow has five stages, each with its own failure modes.
1. Ingestion and normalization
Documents arrive in various formats: PDF, DOCX, scanned image, HTML, email body. The first step normalizes them to a common representation — typically extracted text, with page or section boundaries preserved.
PDF extraction deserves special attention. Programmatic PDFs (generated by software) extract cleanly. Scanned PDFs need OCR. Native PDF tables often extract as garbage. Your pipeline needs to handle all three cases, not just the clean one.
2. Chunking
Raw extracted text is too large to pass directly to an LLM. The text needs to be broken into chunks that fit within the context window, with enough overlap between chunks to avoid splitting semantically coherent passages.
Chunking strategy matters more than most teams expect. Fixed-size chunking is simple but splits sentences. Semantic chunking (splitting on section headers, paragraph boundaries, or sentence embeddings) produces better extraction quality but is more complex to implement and more sensitive to formatting variation in the source documents.
3. Extraction
Pass each chunk to an LLM with a structured extraction prompt: "Extract the following fields from this text: [field definitions with descriptions and examples]." Use schema-constrained output — every extraction result should be validated against a schema before it is used.
For multi-page documents, extraction runs across multiple chunks and the results need to be merged. The same entity may appear in multiple chunks; the merge logic needs to handle deduplication and conflict resolution.
4. Validation and confidence scoring
Not all extractions are equal. An LLM that extracts a contract effective date with high confidence in a clearly formatted clause is different from one that inferred a date from ambiguous context.
Add a validation step that checks extracted values against domain rules (dates are valid, monetary values are in expected ranges, required fields are present) and flags low-confidence extractions for human review rather than passing them through automatically.
5. Output routing
Validated extractions flow to their destination: a database record, a CRM field update, a structured report, a downstream API call. High-confidence results can be processed automatically. Flagged results route to a human review queue.
The reliability requirements
Each document is one run. A document processing pipeline should treat each document as an independent workflow run — one run ID, one trace, one failure domain. A batch that fails on document 47 should not affect documents 48-100.
Idempotency on re-ingestion. When a document is reprocessed (after an error, after a model upgrade, after a rule change), the pipeline should detect that this document has been processed before and either skip or re-run explicitly, not create a duplicate record.
OCR and extraction quality are not deterministic. The same document can produce slightly different extracted text on different runs depending on the PDF library version, the OCR model, and the LLM's behavior on edge cases. Build your downstream consumers to handle minor variation in extracted data, not to assume pixel-perfect repeatability.
At scale
At low volume — tens of documents per day — document processing is a background job. At high volume — thousands of documents per day — it needs proper queue management, concurrency limits to avoid overwhelming downstream APIs, and cost tracking per document type.
The cost structure is dominated by LLM calls on extraction, which scale with document length and the number of fields extracted. Prompt optimization — shorter, more precise extraction prompts — pays dividends at scale in a way it does not at low volume.
AgentRuntime's durable execution model handles document processing pipelines naturally: each document is an independent run, partial failures don't affect the batch, and the human review queue integrates natively with the workflow for flagged extractions. Join the waitlist for early access.